

How To Create A Dbq
dbq
An SQL Command Line Utility
Last update on October 8, 1997
Send questions, comments and corrections to MDMS
Introduction
- user name (-u): franklin
- password (-p): not*a*pswd
- database server (-s): MIPSDB1
- database (-d): catalog
- database command: sp_help
dbq is a command line utility used to send commands to a database and to retrieve results sets and status information. Result data sets are written using the STDOUT file descriptor. Status messages are written using the STDERR file descriptor. By default, both of the theses descriptors send output to your terminal.
While dbq can be used directly from a system prompt in a terminal screen, it was designed mainly for use in command line interpreter script files, offering a method to gain access to database information from within the script. If your database work requires interactive access, see the MDMS utilities dbView and dbWindow; they will server you better. Note: dbView specific commands cannot be used with dbq. dbq can only execute SQL/Sybase ISQL commands.
dbq offers two types of connections. You can supply a user name and password on the command line, in which case, the parameters are used to make the connection. Or, if you are registered with an MDMS password server, the user name and password will be supplied by the server. The connection mode that used a password server is called secure dbq. To find out more about the password server, refer to the Password Server Administration Guide.
To get started, let's look at a simple dbq command that returns results after executing the Sybase Stored procedure sp_help. We must supply parameters to dbq that allow it to connect to the appropriate database server and database along with the command. The entire set of parameters needed are:
The dbq command looks like this:
> dbq -u franklin -p `not*a*pswd' -s MIPSDB1 -d catalog sp_helpThe password is in single quotes to prevent the Unix C Shell from interpreting the character. If you are using a different interpreter, it may or may not be necessary to quote special characters.
A partial listing returned after this command is executed looks like this:
Name Owner Object_type ------------------------ --------------- ---------------------- groupAccounts dbo view groupCharges dbo view groupEmp dbo view missionObjective dbo view myAccounts dbo view myCharges dbo view myEmp dbo view accounts dbo user table attrValues dbo user table attributes dbo user table ...The same command using the password server to provide the user name and password looks like this:
> dbq -s MIPSDB1 -d catalog sp_help
The dbq Environment
- The environmental variable SYBASE (logical name SYS$SYBASE for VMS) must be defined as the directory path for the Sybase interfaces file.
- You must have read access on the Sybase interfaces file.
- Your path must include the directory where a copy of the dbq executable resides. Type the following command to make sure:
> which dbq /usr/local/bin/dbq
- You must have read and execute privileges on dbq.
Before you can run dbq, you must set-up its environment by doing the following:
Command Syntax
The syntax for dbq is shown below.
dbq [-u <userName>] [-p <password>] -s <DataserverName> -d <DataBaseName> [-c {<commandFile> | -}] [-h {yes,no}] [-o <outputFile>] [-f {table, list, export}] [-b <bufferSize>] <command> All arguments except <command> can be place in any order on the command line. The database command must be the last argument. If you include database command in a file, using the -c <command file> argument, you should not include a command on the command line. If you use secure dbq, only the database server name and a command-or command file-are mandatory parameters. Otherwise you must also include a user name and password.
The arguments for the dbq command are defined below:
- -u (+userName) <userName>
- User name used to connect to the target database.
- -p (+password) <password>
- Password that accompanies the user name.
- -s (+server) <DataserverName>
- The name of the database server to which you want to connect. Valid names can be found in your Sybase interfaces file. On Unix machines, use the following command to see the names:
> cat $SYBASE/interfaces
- -d (+database) <database>
- The name of the data to access once a connection is made. If you don't supply this argument, you are connected to your default database.
- -c (+commandfile) {<commandFile> | -}
- The parameter to this argument is the name of a file containing one or more database commands. Each command, or set of command used as a batch, in the file must be terminated with the word "go" placed on a line by itself following the command. Comments can be included in the file. A comment looks like this:
/* This is a single line comment */ /* ** This is a ** multi-line comment */
If you use this option, do not include a database command as a dbq command line argument. - -h (+headers) {yes, no}
- If "no" is specified, the table header and status information normally appearing with data returned by a query are not displayed. Specify "no" when you want only the data returned by a query. The default is "yes": supply header and status information lines.
- -o (+output) <filename>
- If a file name is supplied, information returned by the database server is written to the file. By default, output goes to the terminal screen. On Unix systems, you can simply elect to redirect dbq's output rather than use this parameter.
- -f (+format) {table, list, export}
- By default, rows returned are displayed in table format. You can also choose list or export format.
- The table option outputs the data in tabular form with column headers (unless the command line argument -h no is included).
- The list option outputs each field in a database record on a single line. Records are numbered and separated by a blank line. The format for a field is:
<field name> = <value>
- The export option delimits each record by a newline character (\n) and separates each field with a tab (\t) character. This option is especially useful when returning values to a command line interpreter because there are on extra space characters between values and values with embedded spaces can be manipulated atomically.
- -b (+buffers) <bufferSize>
- This option specifies the size of the program buffer used for returned data. If this option is not specified, the database server default buffer size is used. The default size should be adequate in most cases. Queries returning large amounts of data may require the specification of a larger buffer size.
- <command>
- This is the last argument on the dbq command line. It should not be used if the command includes a file containing commands. The command is a database command sent to the target database. If special characters appear in the command that would be interpreted by your command line interpreter, the special characters, or the entire command, should be "escaped" so interpretation does not occur. Note: VMS users will find that VMS converts the entire command line to lower-case before making it available to dbq. Consequently, when using the VMS version you should encapsulate the entire command in quotes if any part of the command is required to be in upper-case. VMS will leave the quoted portion of the command line untouched.
Exit Values
If dbq can connect to a database server and execute its commands without error, it returns a value of 0. If one or more error occur, it returns a value of 1.
Even though a query may execute properly, it may return no rows, because the query qualified none. In this case, dbq still exits with a value of 0, because the query was executed properly. For queries, after checking the exit status of dbq, check the number of rows returned before proceeding.
The Use Of File Descriptors STDOUT And STDERR
Information associated with results returned, including headers, data, and status lines, are written to STDOUT. Error messages returned from the database server or generated by dbq are written to STDERR.
Terminating dbq With Unix Signals
For Unix environments, if you send dbq a SIGINT (2) or SIGTERM (15) signal, dbq will finish its current command before exiting. All other signals will cause dbq to exit immediately. Signals are normally sent to a process by the Unix kill command; but typing
Representation Of Floating Point Numbers
dbq represents single precision floating point numbers (4 bytes) in decimal format if the number can be expressed by 6 characters or less. Otherwise, scientific notation is used. For double precision numbers (8 bytes), decimal format is used if the number can be expressed by 12 characters or less. Otherwise, scientific notation is used.
Command Line Examples
- The basic command includes the user name, password, server, database and command. The order is not important except that the command must be the last argument.
The query results include, the field names, the line of dashes separating the field names from the data, the data itself, and a status line, telling what was accomplished. In coming example, the status line tells us that 4 rows were affected, or retrieved.
Notice that the entire command must be typed on a single line. If the line is long, just let it wrap to the next line, but don't press the
key before the command is complete. (Pressing the key is the Interpreters signal that the command is complete and should be executed.) > dbq -u franklin -p 'not*a*pswd' -s MIPSDB1 -d catalog Select id, mission, scId from missions order by mission id mission scId ----------- --------------- ----------- 1 Cassini 72 2 GLL 35 3 MO 91 4 VGR 0 (4 row(s) affected)
Notice that the password parameter: 'not*a*pswd' is quoted. That prevents the command line interpreter from trying to expand the string into a set of file names. The parameter in quotes is left uninterpreted. - In the last example, we didn't place quotation marks around the command. This works as long as the command contains characters considered special by the command line interpreter. To avoid any problems, it's best to quote the command. In the C Shell, we use single quotes around the entire command. For any values in the command that require quotes, double quotes are used.
To see what can happened when the command is not properly encapsulated by quotes, let's add a WHERE clause to our command containing the value `GLL':
> dbq -u franklin -p 'not*a*pswd' -s MIPSDB1 -d catalog Select id, mission, scId from missions where mission = 'GLL' MDMS DBS WARNING judith::dbq Wed May 24 15:22:02 1995 (Db: jar, MsgNo: 207, Svr: 16, St: 2) Invalid column name 'GLL'.
The interpreter did not sent dbq what we want it to. Now let's execute the command again, but this time we'll place single quotes around the entire command and double quotes around the value in the WHERE clause:> dbq -u franklin -p 'not*a*pswd' -s MIPSDB1 -d catalog 'Select id, mission, scId from missions where mission = "GLL"' id mission scId ----------- --------------- ----------- 2 GLL 35 (1 row(s) affected)
- We can execute stored procedures as well as SQL commands from dbq. In the next example, the stored procedure showMissions is given a parameter of "GLL" and passed to dbq.
> dbq -u franklin -p 'not*a*pswd' -s MIPSDB1 -d catalog `showMissions GLL' MISSION INFORMATION mission scId objective --------------- ----------- --------------- GLL 35 Jupiter (1 row(s) affected, return status = 0)
The status information now displays the status returned by the stored procedure as well as the number of rows effected. - If our target database is also our default database, we don't need to include the database argument in our command. The last example can be rewritten omitting that argument:
> dbq -u franklin -p 'not*a*pswd' -s MIPSDB1 'showMissions GLL' MISSION INFORMATION mission scId objective --------------- ----------- --------------- GLL 35 Jupiter
Secure dbq
In our last set of examples, we included the password on the command line. This is not a good idea. We strongly recommend that you use secure dbq instead.
Since secure dbq uses Kerberos to authenticate the user, we must run the Kerberos utility kinit first to get a Kerberos ticket granting ticket that can be used by dbq for authentication to the password server. Then, we specify a dbq command without the user name and password on the command line:
> kinit jake SunOS (milano) Kerberos Initialization for "jake" Password: > dbq -s MIPSDB1 "Select id, mission, scId from missions order by mission"
No only is this command secure-the password no longer appears on the command line-but it's also shorter to type in and we don't have to worry about quoting our password if special characters appear in it. (Note: In the rest of the User's Guide examples, we'll assume that secure dbq is used.)Suppressing Headers
When dbq commands are embedded in a script, we often just want the data returned and not the header, status information or blank lines. dbq does this if we include the (-h) option as an argument. Repeating one of our earlier examples with the header option set to `no', we get the following:
> dbq -s MIPSDB1 -h no 'Select id, mission, scId from missions order by mission' 1 Cassini 72 2 GLL 35 3 MO 91 4 VGR 0
Using Command Files
If we want to execute several commands at a time, or if we have "canned" commands that we can easily reference, we can place them in a file and have dbq read the file. Commands in a file are terminated with the word `go' on a line by itself. The file myCommands.sql contains two SQL queries:myCommands.sql select id, mission, objective from missions where mission in ("GLL", "Cassini") go select number, name, lgtYrsFromSun from planets order by number goWe execute the commands in the file by including the name of the file in the dbq command:dbq -s MIPSDB1 -c myCommands.sql 1> select id, mission, objective 2> from missions 3> where mission in ("GLL", "Cassini") 4> go id mission objective ----------- --------------- --------------- 1 Cassini Saturn 2 GLL Jupiter (2 row(s) affected) 1> select number, name, lgtYrsFromSun 2> from planets 3> order by number 4> go number name lgtYrsFromSun ------ --------------- -------------- 1 Mercury 0.00 2 Venus 0.00 3 Earth 0.00 4 Mars 0.00 5 Jupiter 0.00 6 Saturn 0.00 7 Uranus 0.00 8 Neptune 0.00 9 Pluto 0.00 (9 row(s) affected)Since the SQL commands are in a file, they are not passed to the command line interpreter, so there's no need to place them in quotes to prevent special character interpretation.If we have several long queries that we use on a regular basis, we could put each one in a file and then reference each by a file name. We could also create an alias to include the -c option. First, let's create two files, each with a query in it. Commands in a file are executed when the word "go" appears, so we add that after the command in each file:
missions.sql Select id, mission, scId from missions order by mission go gll.sql Select id, mission, scId from missions where mission = "GLL" go
Now a new alias:> alias query "-s MIPDB1 -c"
And we can run commands like this:> query missions.sql <- our input 1> Select id, mission, scId from missions order by mission 2> go id mission scId ----------- --------------- ----------- 1 Cassini 72 2 GLL 35 3 MO 91 4 VGR 0 (4 row(s) affected) > query gll.sql <- our input 1> Select id, mission, scId from missions where mission = "GLL" 2> go id mission scId ----------- --------------- ----------- 2 GLL 35 (1 row(s) affected)
Saving Output To A File
Since dbq write its output using the file descriptor STDOUT, we can save the output to a file by redirecting STDOUT. To redirect output from the Unix C Shell, use something like this: >myFile, or to append to an existing file, use: >>myFile. Lets save the results from the last example to the file named queryResults:
> dbq -s MIPSDB1 -c myCommands.sql >queryResults
To look at the file's contents, we'll use the Unix cat command:> cat queryResults id mission objective ----------- --------------- --------------- 1 Cassini Saturn 2 GLL Jupiter (2 row(s) affected) number name lgtYrsFromSun ------ --------------- -------------- 1 Mercury 0.00 2 Venus 0.00 3 Earth 0.00 4 Mars 0.00 5 Jupiter 0.00 6 Saturn 0.00 7 Uranus 0.00 8 Neptune 0.00 9 Pluto 0.00 (9 row(s) affected)
If we're using an interpreter that can't redirect dbq's output, we can use the -o option to obtain the same effect. Note: files created with the -o option always overwrite a file with the same name if it the file already exits. You can't append data to a file with this option.Putting the -o option in our last example would look like this and achieve the same result:
> dbq -s MIPSDB1 -c myCommands.sql -o queryResults
Error Messages
If we issue a database command that can't be executed for some reason, dbq returns an error message. All such messages are written using the STDERR file descriptor, so we can redirect them to a file. Since all data is returned to STDOUT, any data would be displayed, unless STDOUT was redirected to a file too.For example, if we can't connect to a server for some reason-it may not be running, or we may use incorrect connection information-we get a message. In the following example, we've specified the database server name incorrectly:
dbq -s MIPDDB1 -d catalog 'select id, mission, from missions' MDMS DBLIB MSGFAILED judith::General Delivery Thu May 25 08:24:01 1995 MsgNo: 20012, Svr: 2 Server name not found in interface file.
The first line of the message tells us where the message was originated and at what time. The second line gives us the message number and its severity. The third line is the one we want to pay attention to initially-it tells us what went wrong. In this case the server name was not in the Sybase interfaces file, so dbq could not find the information it needed to connect to a server.If we specify a database command incorrectly, dbq will also send an error message. In the next example, the column named missions should have been mission - without a final `s'.
dbq -s MIPSDB1 'select id, missions, description from missions' MDMS DBS WARNING judith::dbq Thu May 25 08:15:23 1995 (Db: jar, MsgNo: 207, Svr: 16, St: 2) Invalid column name 'missions'.
dbq is primarily meant to be used in scripts executed by a command line interpreter. But before looking at that type of application, it's a good idea to become familiar with dbq itself and ways of applying it. So in this section we'll look at dbq examples that can be executed directly from a terminal command line. The examples were run from the Unix C Shell, put similar results can be obtained in other environments.
Simple Commands
Using Aliases With dbq
The basic dbq command takes the same set of arguments each time. In Unix environments we can shorten the amount of typing necessary and make the command easier to remember by creating an alias. For example:
> alias query "dbq -s MDM1 -d catalog"Now we can specify a database command using just the alias "query" followed by the command:
> query 'Select id, mission, scId from missions order by mission' id mission scId ----------- --------------- ----------- 1 Cassini 72 2 GLL 35 3 MO 91 4 VGR 0 (4 row(s) affected)Or, specifying a command as a quoted string:
query 'Select id, mission, scId from missions where mission = "GLL"' id mission scId ----------- --------------- ----------- 2 GLL 35 (1 row(s) affected)Note: As much as you might like to, don't save you alias in a file if the alias contains you password. That is a security violation. Take a moment in a new session to recreate the alias. If you're using secure dbq, then you can save the alias.
As we've mentioned before, dbq is meant to be used in command line interpreter scripts. Most interactive work is done in dbView or dbWindow. But there can be commands at you want to get at rapidly without going into a database sessions. Here's one example that could be useful; it shows the amount of database activity by displaying the list of users:
> alias dbwho "-s MDM1 sp_who"Whenever we execute dbwho, we see something like this:
> dbwho spid status loginame hostname blk dbname cmd ------ ------------ ------------ ---------- ----- ---------- ---------------- 1 recv sleep devServer venatia 0 fei2_0 AWAITING COMMAND 2 sleeping NULL NULL 0 master NETWORK HANDLER 3 sleeping NULL NULL 0 master MIRROR HANDLER 4 sleeping NULL NULL 0 master CHECKPOINT SLEEP 5 running franklin milano 0 franklin SELECT (5 row(s) affected, return status = 0)
Embedding dbq In Perl Scripts
In this section, we'll show how dbq commands can be embedding in script files. For our examples, we'll use Perl, an interpretive language that combines the functionality of Unix shells, awk, sed, grep and C-to some extent. Perl is available for most operating system environments, so the scripts are portable; it's free; and the language is quite powerful and well suited to the kind of work we want to do.
Wether or not you choose to use Perl, the examples in this section will show you how dbq can be embedded in a command interpreter script. After seeing the possibilities, you can go off and create your own scripts for the interpreter of you choice.
Since these examples tend to be lengthy, you can find copies of them in the same directory where you found this user's guide. Feel free to modify the scripts. The scripts are unsupported so you are on your own if you use them. However, you can send bugs reports and suggestions to the email address listed in the on-line examples. If changes are made as a result of your message, we'll send you an update copy of the script if you request it.
Making A Perl Script Executable
Before you can run any of these examples, you'll have to make them executable with the command:
> chmod u+xor for groups of users
> chmod g+rxTo make the examples available to everyone, you should place the scripts in a directory available to all users. For Unix environments, make sure the directory is included in the standard PATH definition of each user so users can run them.
Basic Perl Constructs Used With dbq
For our first Perl example, we show how to retrieve rows from a database and manipulate them within a Perl script. We'll focus on basic steps in this example and then go on to show how the example can be modified to start a process, passing it parameter derived from database data.The basic Perl script for dbq has the following structure:
- Define the dbq command.
- Get the database server password and substitute it into the command. (If you're using secure dbq, this step can be skipped.)
- Run dbq and execute a database command. Check to make sure the command ran correctly and rows where returned if the command contained queries.
- For each row returned, split the row's contents into fields. Print the field values for each row or use the values for further processing.
Define The dbq Command
For our example, we'll execute the SQL command:Select fileName, filter, ert from gllSsiEdr where receivedAt > "5/27/95 12:00"The query states that we want the file name, filter value and ert date (Earth Receive Time) for every Galileo SSI ERT file received later than May 27, 1995 at noon.
The parameters supplied with the dbq command are:
dbq -u franklin -p `%s' -s MIPSDB1 -d %s -h no -f exportThe password value is defined as `%s' for two reasons. First, the single quotes tell the Perl interpreter not to evaluate the string contained by the quotes. This allows us to use special characters in passwords, as in the string: `not*a*pswd'. Second, we don't want to hard-code the password in the script where it could easily be discovered by someone else. Instead, we'll prompt for the password from a function that won't echo the password as we type it in. The value we supply will be substituted for the symbol `%s' in the dbq command string.
We'll also get the database parameter for the dbq statement at run time. We'll pass this parameter on the Perl script's command line. We could use this technique to alter any of the dbq arguments at run time; in that way, generalizing our script. The "-h no" argument is included so dbq will not print header and status information for the query. Normally in a Perl script, we're only interested in the rows returned by a query. Including header and status information would just mean that we'd have to parse the data returned to get just the rows returned.
The -f export argument is supplied because we don't want values returned to be padded with blanks as they are when using table format. If dbq put in extra spaces, we'd just have to take them out again. There is second reason for using export mode. In this mode, fields are delimited by the tab character (\t). Since each row is returned as a string, we have to split the fields out of the row using some field delimiter. We don't want to use a space character, because fields in the row can contain spaces. For example, a date, like the ert field in the query, contains spaces in it: "May 7 1995 13:30:00AM" for example. The tab delimiter allows us to easily separate the entire data value from the row.
Now let's look at the code segment that describes the dbq command:
$dbq = "dbq -u franklin -p '%s' -s MIPSDB1 -d %s -h no -f export 'Select fileName, filter, ert from gllSsiEdr where receivedAt > \"5/27/95 12:00\"'"; $dbq =~ s/\n/ /g;The dbq command arguments appear on a line. The query follows, broken into several lines so that we can easily read it. Let's pay careful attention to how quotes are used in this command:
- The entire command is placed in double quotes. Everything in the double quoted string is assigned to the variable $dbq.
- The SQL command is in single quotes so nothing within it will be interpreted.
- SQL requires the value for the receivedAt field be quoted. Since the entire SQL statement is in single quotes, we use double quotes around the date value. But we're already using double quotes around the entire statement that we assign to the variable $dbq, so we need to "escape" the quotes around the date so Perl will ignore them when making the assignment.
The line following the assignment of $dbq:
$dbq =~ s/\n/ /g;does a global substitution in the string assigned to $dbq, replacing the newline character (\n) with a space. Why is this necessary? The dbq command can't contain newlines; a newline character signals the end of the command, so we take them out. But then, why did we put them in the first place? We did it to make the database command easier to read and to make replacing the command easier if we were to use this code in another script.
Getting The Target Database Name
The name of the Perl script we're creating is called: basicDbq.p. When we run the script we place the database name on the command line as the argument for the script:
> basicDbq.p catalog ? the target database nameWhen the script is run, we check to see if the argument was supplied. If not, we exit with a message explaining what the command requires. If the argument is supplied, we assign it to the variable $targetDb. (This assignment is necessary. We do it to make the script more readable.)
unless (defined $ARGV[0]) { print "You forgot to include the target database name.\n"; print "Usage: $0 targetDatabase\n"; exit 1; } $targetDb = $ARGV[0]; ($0 is the Perl variable that contains the name of the script. We use it rather than the hard-coded name so the name of the script can be changed and the message remains accurate.) Later, once we have the password, we'll substitute the value of $targetDb into the dbq command string.
Getting The Password
The following lines of code call a subroutine to get the password. Once we have it, it substitute it and the target database name into the dbq statement.
&pswd; $dbq = sprintf ($dbq, $password, $targetDb);After the substitutions are made, the dbq command string looks like this:
$dbq = "dbq -u franklin -p 'not*a*pswd' -s MIPSDB1 -d catalog -h no -f export 'Select fileName, filter, ert from gllSsiEdr where receivedAt > \"5/27/95 12:00\"'";The subroutine that gets the password does two special things. First it turns off terminal echo of keyboard events while the password is typed in so the password can't be seen. Second, it ignores the signal SIGINT while echo is turned off. SIGINT is generated when we type
Here is the code for the password subroutine. The chomp function removes the newline character supplied with the user input string.
You should include this subroutine, or one like it, in any script that requires a password for dbq:
sub pswd { $SIG{'INT'} = 'ignore'; system 'stty', '-echo'; print "password: "; chomp ($password = ); system 'stty', 'echo'; print "\n"; $SIG{'INT'} = 'default'; } Executing The Command
Executing the command and getting the rows returned is easy. Here's the three lines of code that do it:
@rows = `$dbq`; #if ($? >> 8) { exit 1;}; unless ($#rows +1) {exit 0;} The dbq command variable is "backquoted". This tells Perl to execute the command and return the output of the command as a string. This string is assigned to the array @rows. Since dbq's output contains newline characters at the end of each row, each row becomes an element in the array. So now we have the data back in an array of rows. Before processing the rows. we have to look at two things: the return value of dbq and the number of rows returned. If the command failed or there were no rows returned, there's nothing left to do, so we exit. The second line of code:
#if ($? >> 8) {exit 1;}; test the exit value of the command. The value is stored in the top byte of a two byte Perl variable, $?. To test the value, we shift the bits by 8 and test. If the value is not 0, we exit with a value of 1, indicating an error. To find the number of rows returned, we look at the number of elements in the array @rows. If there are no elements, no rows were returned, so we exit with a value of 0, meaning the program executed properly, but there's nothing left to do. The number of elements in the array is stored in the Perl variable $#rows. Since the first element of an array is 0, we add one to the value to get the row count. This is done in the third line of code:
unless ($#rows +1) {exit 0;} Processing The Rows Returned
If rows were returned, we display the fields for each row with the following code:print "\n"; foreach $row (@rows) { ($fileName, $filter, $ert) = split ('\t', $row); print "file name: $fileName, filter: $filter, ERT: $ert\n"; } print "\n"; The foreach loop assigns an element of the array @rows to the scalar variable $row each time through the loop. The split function, splits the string into elements. The character used to denote a split is the tab (\t) because that separates fields when using the dbq export format. We then print the field values for each row. The loop is surrounded by two newlines so that the output is isolated from other information appearing on the screen.
Executing A Perl Script
Before we can run a Perl script, we must change its permissions to make it executable:> chmod u+x basicDbq.pAnd to do it for every member in our group, we use this:
> chmod g+rx basicDbq.pIf we want a group of people to be able to execute the command, we put the Perl scripts in a directory that is referenced by the PATH variable for our group.
Now let's run the script and see what happens.
> basicDbq.p catalog password: file name: file125.edr, filter: C, ERT: May 27 1995 1:45:47:166PM file name: file126.edr, filter: A, ERT: May 27 1995 2:10:32:203PM file name: file127.edr, filter: B, ERT: May 27 1995 2:40:46:220PM file name: file128.edr, filter: C, ERT: May 27 1995 3:08:12:236PMWe typed in the command suppling the target database name on the command line. Once the script runs, we're prompted for the password, which we enter. The dbq command is executed and the data returned from the database server is displayed.
Perl Script basicDbq.p
Here's the entire script. Just change the database command and the output lines in the foreach loop and you've go your own script.
The script appears much longer that the actual code warrants because the script is so heavily commented. In your version, you may want to illuminate some of the comments.
#! /usr/local/bin/perl # # Usage: # basicDbq.p targetDatabase # # Description: # An example showing the basic Perl script constructs used when # executing a dbq command and processing the rows returned by a # query. # # Written by: # John Rector # Jet Propulsion Laboratory # jar@next1.jpl.nasa.gov # # History: # June, 1995 1.0 - initial release # # Version: # 1.0 # Check to make sure that the target database name was supplied on the # command line. If not exit with a message. unless (defined $ARGV[0]) { print "You forgot to include the target database name.\n"; print "Usage: $0 targetDatabase\n"; exit 1; } $targetDb = $ARGV[0]; # Define the basic parameters for the dbq command used in a Perl script. # Follow that with the database command. We use multiple lines here to # make the command more readable. Do a global substitution to remove # the newlines we used to make the command readable. The Perl interpreter # expects the dbq command to be on a single line. $dbq = "dbq -u franklin -p '%s' -s MIPSDB1 -d %s -h no -f export 'Select fileName, filter, ert from gllSsiEdr where receivedAt > \"5/27/95 12:00\"'"; $dbq =~ s/\n/ /g; # Subroutine to get the password for the command. Don't put passwords in # a script file; it's a security violation. Use this method or use secure # dbq which gets the password from a password server. Once we have the # password, insert it into the dbq command, replacing %s. Note that the # password string is placed in single quotes so special characters in # the string won't be interpreted. &pswd; $dbq = sprintf ($dbq, $password, $targetDb); # Execute the command using the Perl backquote invocation method. This # will cause Perl to treat the value printed by the command (a set of # database rows) as a string. The rows returned are assigned to the # array @rows. The newline character at the end of each row retuned by # dbq cause Perl to enter the row as an element in the array. # # Test to see if the command was executed correctly. The return value is # stored in the high byte of the Perl variable '$?'. Shift the value by 8 # bits to look at the dbq exit value. If everything went OK, dbq's exit # value will be 0; otherwise it's 1. # # Then test that rows were returned. '$#rows' is the number of the last # element in the array, so the number of rows is one more than that. # (The first element in the array is number 0.) @rows = `$dbq`; #if ($? >> 8) { exit 1;}; unless ($#rows +1) {exit 0;} # Go through the array, one element, or row, at a time. Split each row # into fields and print the fields. Since we're using dbq's export format, # we want to split on tabs (\t). Spaces in fields are preserved using # this technique. # Newlines are place around the print out so that the rows are isolated # on the screen. print "\n"; foreach $row (@rows) { ($fileName, $filter, $ert) = split ('\t', $row); print "file name: $fileName, filter: $filter, ERT: $ert\n"; } print "\n"; ################# # Subroutine pswd ################# sub pswd { # Prompt for a password. Turn off terminal echo so we don't see the password. # Ignore SIGINT during this time so we can't use to terminate # the program, leaving us in a state where input is not echoed to the screen. # Remove the last character (a newline) of the input string with the chop # command. $SIG{'INT'} = 'ignore'; system 'stty', '-echo'; print "password: "; chop ($password = ); system 'stty', 'echo'; print "\n"; $SIG{'INT'} = 'default'; } Supplying Database Values At Run Time
- Supplying the values to the program as scalar values on the program's command line.
- Supplying a list of files names to the program for processing.
- Writing a list of file names to a file and then passing the name of that file to the program.
In this section we'll alter basicDbq.p so that the parameters returned for each row are supplied to a program which is then run from the Perl script. We'll look at three cases:
For our examples, we'll use a test program named testProc that just prints out its name and its argument list.
Supplying Scalar Values On The Command Line
The foreach loop in basicDbq.p is altered to look like this: foreach $row (@rows) { ($fileName, $filter, $ert) = split ('\t', $row); system ("testProc", "$fileName", "$filter", "$ert"); } We substitute the line in bold for the print statement in basicDbq.p. The system function runs the program testProc, passing it the values for $fileName, $filter and $ert with each pass through the loop. Now when we run our Perl script the program testProc prints it arguments to the screen:
./testProc Argument 0: file125.edr Argument 1: C Argument 2: May 27 1995 1:45:47:166PM ./testProc Argument 0: file126.edr Argument 1: A Argument 2: May 27 1995 1:45:47:203PM ./testProc Argument 0: file127.edr Argument 1: B Argument 2: May 27 1995 1:45:47:220PM ./testProc Argument 0: file128.edr Argument 1: C Argument 2: May 27 1995 1:45:47:236PM
Using An Array Of Arguments
It's not uncommon for a program to take a list of file names as arguments. If we're using such a program, we can modify basicDbq.p to efficiently handle this case. First, we modify the SQL statement to only return the file name:$dbq = "dbq -u jar -p '%s' -s MDM1 -d %s -h no -f export 'Select fileName from gllSsiEdr where receivedAt > \"5/27/95 12:00\"'";And then we replace the foreach loop with the following single line of code:
system ("testProc", @rows); Now when we run our Perl script each of the file names returned from the database is contained in the array @rows, which we pass as a list to the program testProc. Since we only need to call testProc once with the list of file names, our design is more efficient. Here's what the output looks like:
./testProc Argument 0: file125.edr Argument 1: file126.edr Argument 2: file127.edr Argument 3: file128.edr
Writing Arguments To A File
If the program we want to pass database information to, reads a list of file names from a file-or a set of information for that mater - we can easily do that, too.
We'll use the array of file names as we did in the last example. Again, we'll replace the foreach loop in basicDbq.p. The replace code is shown below:
$" = "\n"; open (OUT, ">inputFile"); print OUT @rows; close OUT; system ("testProc", "inputFile"); The first line changes the array element separator from its default value of a space to the newline character. In the next three lines, we open the file inputFile and write the array elements to it and then close the file. The file now contains the file names returned by dbq. Each is separated by a newline character in the file. Finally we call testProc and pass it the name of the file containing the file names, which is reads, one record at a time: ./testProc File name: file125.edr File name: file126.edr File name: file127.edr File name: file128.edr
Summary
Using the script basicDbq.p and these simple modifications will allow you to build scripts to handle many common processing tasks that involve getting meta-data from a database and then using it to perform processing steps.
A Script That Returns A Large Number Of Rows
In our previous examples, we returned the row set from the database to an array. When we don't have a large number of rows to return that's a good method, but if we're concerned about the amount of memory taken up by the array, we can use an alternate method that returns one row at a time to our program, much as though we we're reading lines from a file.
To do this, we'll pipe the output from dbq into our Perl script-we call the Perl script readRows.p. To start with, we'll open the pipe from dbq and associated it with a file descriptor named DBQ in our Perl script:
open (DBQ, "$dbq |") || die "Can't open $dbq: $!\n";
We're using the same definition of $dbq that we used in basicDbq.p. The vertical bar associated with the variable: "$dbq |" indicates that we want the output of dbq piped directly to the Perl script's DBQ file descriptor. This form of the Perl open function also implicitly runs the dbq command for us.
The rest of line:
|| die "Can't open $dbq: $!\n";tells the script to exit if the command cannot be executed and to print out the quoted string following the word die. $! is a Perl variable that holds the message associated with the system errno value. This too is printed.
The open function replaces the following line in the script basicDbq.p:
@rows = `$dbq`;To read the rows one at a time, we make an assignment to $row using the newly defined file descriptor, DBQ. Each time through the while loop another row is read from dbq. When there are no more rows to be read, the loop exits.
$count = 0; while ($row =We initialize a count variable to 0 before entering the loop and then increment it each time a row is read. Once we exit the loop, we execute the following command:) { ($id, $mission) = split ('\t', $row); print "id: $id, mission: $mission\n"; $count++; }
print "No rows returned\n" unless $count;Which prints out "No rows returned" if the count is still 0.
The while loop replace the following foreach loop in the script basicDbq.p:
foreach $row (@rows) { ($id, $mission) = split ('\t', $row); print "id: $id, mission: $mission\n"; } Executing readRows.p
After making these few simple changes to basicDbq.p to create addRows.p, we can run the script. The output is the same, but we didn't use an array to capture the rows returned by the query this time.
> readRows.p catalog password: file name: file125.edr, filter: C, ERT: May 27 1995 1:45:47:166PM file name: file126.edr, filter: A, ERT: May 27 1995 2:10:32:203PM file name: file127.edr, filter: B, ERT: May 27 1995 2:40:46:220PM file name: file128.edr, filter: C, ERT: May 27 1995 3:08:12:236PM
Perl Script readRows.p
Here's the entire perl script. The code changes from basicDbq.p are marked in bold type. We've removed the tutorial comments in this script so you can better see the script's structure.
#! /usr/local/bin/perl # # Usage: # readRows.p targetDatabase # # Description: # A basic Perl script for returning a large number of rows from a dbq query. # Rows are piped from dbq's STDOUT file descriptor to Perl. # # Written by: # John Rector # Jet Propulsion Laboratory # jar@next1.jpl.nasa.gov # # History: # June, 1995 1.0 - initial release # # Version: # 1.0 # Check to make sure that the target database name was supplied on the # command line. If not exit with a message. unless (defined $ARGV[0]) { print "You forgot to include the target database name.\n"; print "Usage: $0 targetDatabase\n"; exit 1; } $targetDb = $ARGV[0]; # Dbq command with query. We remove the newlines after the query is defined. $dbq = "dbq -u franklin -p '%s' -s MIPSDB1 -d %s -h no -f export 'Select fileName, filter, ert from gllSsiEdr where receivedAt > \"5/27/95 12:00\"'"; $dbq =~ s/\n/ /g; # Get the password and substitute it into the dbq command. &pswd; $dbq = sprintf ($dbq, $password, $targetDb); # Execute the dbq command and pipe results back to the file descriptor DBQ. # Check for errors. open (DBQ, "$dbq |") || die "Can't open $dbq: $!\n"; #if ($? >> 8) { exit 1;}; # Read each row and print out the field values. Keep a count of the # number of rows. print "\n"; $count = 0; while ($row = ) { ($fileName, $filter, $ert) = split ('\t', $row); print "file name: $fileName, filter: $filter, ERT: $ert\n"; $count++; } print "\n"; # Print this is the count is 0. print "No rows returned\n" unless $count; ################# # Subroutine pswd ################# sub pswd { $SIG{'INT'} = 'ignore'; system 'stty', '-echo'; print "password: "; chop ($password = ); system 'stty', 'echo'; print "\n"; $SIG{'INT'} = 'default'; } dbq In A Batch Processing Script
In this example, we create a batch program that meets the following requirements:
- The process must run continually in the background until it receives a signal. Either SIGTERM or SIGINT will terminate gracefully, meaning that any processing occurring when the signal is received will complete before processing stops.
- At a specified time each day, the process will query the target database for all new files of the type gllSsiEdr and return the file name, filter type and ERT value for each entry found.
- For each file name returned, a process will be run with the command line values: file name, filter type and ert value. (For our example, the process is called testProc.)
- After processing is complete, the list of files processed will be emailed to franklin@hardKnocks@edu.
We'll look at a solution to each of these requirements in turn. At the end, we integrate the solutions into a program named batch.p which is listed at the end of this example.
Creating A Background Process
Since our batch process must run continually, until signaled, we create a main loop that continues to execute until the variable notDone is set to 0. Here some skeletal code to meet the requirement:
$SIG{'INT'} = 'sigHandler'; $SIG{'TERM'} = 'sigHandler'; $notDone = 1; while ($notDone) { get information from a database Invoke a process using the values found in a row of database data. } exit 0; ####################### # subroutine sigHandler ####################### # Captures SIGINT and SIGTERM. Sets the main loop variable, so the program # exits on the next pass through the loop. sub sigHandler { $notDone = 0; } We begin by defining a subroutine to be called when either a SIGINT or SIGTERM signal is received. Then we go into a loop that executes the work needed to be done as long as the variable $notDone is some value other than 0. When we exit the loop, the program exits. The subroutine sigHandler is called when the program receives the signal SIGINT or SIGTERM. It sets the value of $notDone to 0, so the program exits the main loop the next time through.
Putting this code in batch.p and invoking the program as a detached process, satisfies the first requirement. Using the Unix C Shell, we would invoke the program like this:
> batch.p <argument list> &
Executing A Query At A Specified Time
To execute a query at a specified time, we include the time as one of batch.p's arguments. The time is specified to the minute and uses a 24 hour clock, so a time value of 2:00 means two o'clock in the morning and 14:00 means two o'clock in the afternoon.
We want to sleep at the beginning of the main loop. This code fragment will do it:
unshift (@INC, "/home/jar/Perl/Dbq"); require "sleepTill.pl" || die "Can't locate sleepTill.pl package\n"; ... $notDone = 1; while ($notDone) { &sleepTill'tomarrow ($ARGV[1]); /* get information from a database */ /* Invoke a process using the values found in a row of database data. */ } The first two lines in bold type, bring in a Perl package that contains a subroutine that will cause the program to execute at a specified time each day. The first line, tells us where to find the file that contains the package we want. Unshift puts the directory specification at the front of the array @INC so that directory is always searched first. Require is the command that reads and executes the code in the file sleepTill.pl-pl for Perl library.
The third bold line-the one in the while loop-causes the program to sleep until the time specified by the variable $batchTime. The string: &sleepTill'tomorrow ($ARGV[0]) has four components:
- & - This is the subroutine reference symbol.
- sleepTill' - This is the name of the package in which the subroutine is located; it's the same name as the file we brought-in the earlier require function. Subroutines in a package are encapsulated by the package. So, to call the subroutine, we include the packaged name. The subroutine names follows the apostrophe after the package name.
- tomorrow - This is the name of the subroutine in the package that we want to call. It causes the program to wait until the time specified by its argument.
- $ARGV[1] - @ARGV is the built-in array of command line arguments. We include the time to start processing as the second element on the command line, $ARGV[1], because arrays start at index 0.
We don't have to know what tomorrow actually does; we just have to know how to call it. The code for the sleepTill package is in the appendix to this guide.
The bold line in the code calls the subroutine tomorrow with the variable $batchTime. $batchTime is the argument we pass to the programming containing our time value.
Now that the program sleeps as intended, we want to get data from the database to complete our second requirement. We do that with the following code segment:
$sql = "Select fileName, filter, ert, receivedAt from gllSsiEdr where receivedAt > \"$filesLaterThan\""; ... &dbqServer'connect ("MIPSDB1", $ARGV[0], $logFile); $notDone = 1; while ($notDone) { &dbqServer'cmd ($sql); if (defined @dbqServer'rows) { foreach $row (@dbqServer'rows) { ($fileName, $filter, $ert, $filesLaterThan) = split ('\t', $row); } } elsif (defined @dbqServer'error) { print LOG @dbqServer'error; } } $dbqServer'disconnect; The code begins with the definition of the query to perform. The query's WHERE clause gets rows where the receivedAt value is later than a specified date and time; the value for the date and time is held in the variable $filesLaterThan. The first time through the loop, $filesLaterThan is set to a default value or to the value supplied on the command line as the third argument, $ARGV[2]. After that, the value is reset each time we get a row back from the database, because $filesLaterThan is one of the values split out from $row. The next time through the main loop, $filesLaterThan will hold the value returned by the last row of the query executed on the previous day. To get the data, we referenced three subroutines and two variables from the package named dbqServer. We use a require statement to load the package just as we did for sleepTill. Again, we don't need to know what dbqServer does, just how to use it. (The code for the package dbqServer is in the guide's appendix.) Here's a discussion of how each dbqServer subroutine and variable is used by our program:
- &dbqServer'connect ("MIPSDB1", $ARGV[0])
- This starts a copy of dbq as a separate process than can communicate with batch.p. The two arguments are the database server, target database ($ARV[0]) to be used with the dbq command. Secure dbq is used, so no user name or password is required.
- &dbqServer'cmd ($sql)
- Once connected to dbq, we call this command to execute a database command and to return a row set.
- $dbqServer'disconnect;
- Just before exiting, we call the last of the three subroutines. This one closes the communication connections and kills the dbq process.
- @dbqServer'rows
- @dbqServer'rows is not a subroutine; it's the array holding the rows returned after a database command is executed. We first check to see if the variable is defined. If not, an error occurred and no rows were returned. If rows we're returned, we split the values out of each row to use when processing.
- Notice that one of the values split is $filesLaterThan. This is the value used in our query, so each time we read a row, we're resetting that value in the query.
- We split the values using a tab (\t) as a delimiter because dbq was run with export format.
- @dbqServer'error
- If @dbqServer'rows was not defined, we assume that an error occurred. We can check this by seeing if @dbqServer'error is defined. If it is, then an error did occur. The text of the error returned by dbq is in the array. Since we have a way of detecting errors and since we have the error message, we can take appropriate action, including writing the message to a log file.
These steps take care of the second requirement.
Post-Processing Using Database Data
Once we have a row of data back from the database and the value split-out from the row, we want to use the data for a post-processing step. Normally we'd do something real work here, but for our example, we just pass the database values to a process called testProc which write the values along with a time stamp to the file named testProc.out. The code that does this is show by the single line in bold below:
while ($notDone) { ... &dbqServer'cmd ($cmd); if (defined @dbqServer'rows) { foreach $row (@dbqServer'rows) { ($fileName, $filter, $ert, $filesLaterThan) = split ('\t', $row); system ("testProc", "$fileName", "$filter", "$ert"); if ($? >> 8) { $message = "testProc failed with status: " . ($? >> 8); &mail'message ($message); } } } } ... The first parameter to the system function is the program name. The next three are the database values passed as command line arguments. The last parameter writes any messages from testProc to the log file shared with batch.p. We don't have to worry about error messages getting mixed in the shared file because the writes are flushed when the program exits and batch.p flushes it's error messages immediately. The next three lines test return code of testProc. If it's not 0, a message is mailed using the package mail.
Mailing Results
We mail messages to franklin@hardKnocks.edu with the subroutine message in the package mail. Each time a row is retrieved, a mail message is sent with the following lines of code:
foreach $row (@dbqServer'rows) { ($fileName, $filter, $ert, $filesLaterThan) = split ('\t', $row); $message = "batch.p: Processing file: $fileName\n"; &mail'message ($message); system ("testProc", "$fileName", "$filter", "$ert"); } Summary
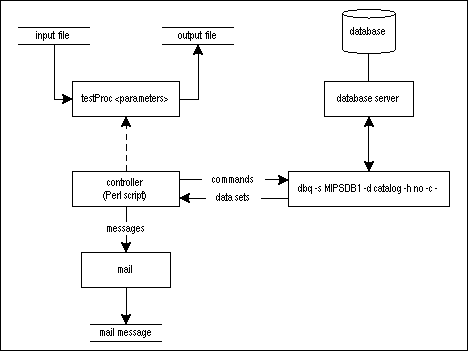
That complete our discussion of batch.p. The diagram below shows the processes involved. We changed testProc in the diagram to show that it is intended to read a file named as one of its command line arguments and to write a new file after a processing step.
An example batch.p command looks like this:
> batch.p catalog 2:00 5/27/1995 &This runs the process in the background with the parameters:
- Target database: catalog.
- Time at which to start batch job each day: 2:00 AM.
- The first time through, find files with a receivedAt date later than: May 27, 1995 12:00:00 AM.
The script for batch.p can be found in the appendix to this document.
Appendix: Perl Scripts
Perl Script: dbqServer
#! /usr/local/bin/perl # # Usage: # dbqServer # # Description: # The package contains the following subroutines: # # connect - Does a fork and exec on dbq with appropriate parameters # for a secure connection. Two pipes are established. Command are sent # on CMD_OUT. Data is read on DATA_IN. # # cmd - Take a database command and sends it to dbq using CMD_OUT. # Results are received on DATA_IN. Error detection is included. # # disconnect - Closes the pipes and kills dbq. # # Each time cmd is executed, the rows returned are left in the array # @dbqServer'rows. If there are no rows or an error occured, # @dbqServer'rows is undefined. Also, if an error occured $dbqServer'error # has a positive value. # # Written by: # John Rector # Jet Propulsion Laboratory # jar@next1.jpl.nasa.gov # # History: # June, 1995 1.0 - initial release # # Version: # 1.0 package dbqServer; # Create a dbq process that can talk to its parent. Commands are sent # from the parent to dbq with CMD_OUT. Data is received with DATA_IN. sub connect { if ($#_ < 2) { print "Too few arguments passed to dbqServer'connect.\n"; last; } $dbSrv = @_[0]; $db = @_[1]; $logFile = @_[2]; # Open two pipes: one for piping commands from the parent process to dbq # and a second for piping data from dbq to the parent. pipe (CMD_IN, CMD_OUT); pipe (DATA_IN, DATA_OUT); # Fork and exec dbq. The dbq's pid is returned to the parent. The # dbq process's pid is defined as 0. $dbqPid = fork (); if ($dbqPid != 0) { # parent # Close the ends of the pipe not used and force non-buffered I/0 # on the others. Reselect STDOUT as the default file descriptor # used by the print function. close (CMD_IN); select (CMD_OUT); $| = 1; select (DATA_IN); $| = 1; close (DATA_OUT); select (STDIN); $| = 1; select (STDOUT); } elsif (defined $dbqPid) { #child: dbq # Close the ends of the pipe not used and force non-buffered I/0 # on the pipes used. select (CMD_IN); $| = 1; close (CMD_OUT); close (DATA_IN); select (DATA_OUT); $| = 1; # Redirect STDIN, STDERR and STDOUT to the pipe descriptors # so they'll be used when we exec dbq. Again, non-buffered IO. close (STDIN); open (STDIN, "<&CMD_IN"); select (STDIN); $| = 1; close (STDERR); open (STDERR, ">&DATA_OUT"); select (STDERR); $| = 1; close (STDOUT); open (STDOUT, ">&DATA_OUT"); select (STDOUT); $| = 1; # Exec the dbq command with the following command line arguments. $dbqCmd = "-s $dbSrv -d $db -h no -c stdin >>$logFile"; exec "$dbqCmd" || die "Can't exec dbq: $!\n"; exit 0; } else { # weird fork error die "Can't fork: $!\n"; } } # First argument is the command to send to dbq. Result rows and error # messages are returned to the array @rows. Command ends with a row # containing nothing, terminated with a newline character. sub cmd { local ($row); $error = 0; @rows = (); # Remove any newlines from the command and send it as a single # string. Follow that with the dbq end-of-command signal. $_[0] =~ s/\n/ /g; print CMD_OUT @_[0]; print CMD_OUT "\ngo\n"; # Get a row. Check for an error - string beginning with MDMS. # If no error, push the row onto the stack until last-row indicator - # an empty row. If error, print the message and undef @rows; there's # no data to access. Test for error is on the value of $error; 1 if # error. while (1) { $row = ; $error = 1 if ($row =~ /^MDMS/); last if $row =~/^\n/; push (@rows, $row); } if ($error) { open (LOG, ">$logFile"); print LOG @rows; close LOG; undef @rows; } } # Close the pipes and kill this instance of dbq. sub disconnect { close (CMD_OUT); close (DATA_IN); kill 15, $dbqPid if defined $dbqPid; } 1; # The require function will fail without this. Perl Script: sleepTill
# Usage: # sleepTill # # Description: # Each time the subroutine tomorrow is called, the program will sleep # until the time defined by the variable $batchTime. $batchTime is # passed as the first parameter to the subroutine tomorrow. # The syntax for the $batchTime value is: # # : # # For example: 2:00 - two o'clock in the morning. 14:00 - two o'clock # in the afternoon. # # Written by: # John Rector # Jet Propulsion Laboratory # jar@next1.jpl.nasa.gov # # History: # June, 1995 1.0 - initial release # # Version: # 1.0 package sleepTill; sub tomorrow { # Store the time at which the program should awake each day in $batchTime. $batchTime = @_[0]; # In seconds for today, what time is it now? ($sec, $min, $hour) = localtime (time); $now = $min * 60 + $hour * 3600; # In seconds for the day, when do we start? unless (defined $then) { $batchTime =~ /(\d+):(\d+)/; $then = $2 * 60 + $1 * 3600; } # Compute the number of seconds to sleep for now til then; then # being the next time a batch job should start. Sleep for that # number of seconds. if ($now > $then) { $seconds = 86400 - $now + $then; } else { $seconds = $then - $now; } $seconds = 5; # for testing only. sleep $seconds; } 1; # Needed so the require function works. Package: mail.pl package mail; sub init { open (LOG, ">$_[0]") || die "Can't open $_[0]: $!\n"; $useLog = 1; } sub message { chop ($date = `date`); print LOG "\n", $date, " $_[0]" if defined $useLog; open (MESSAGE, "| mail -s \"filterProc.p failure report\" jar@next1"); print MESSAGE "$msgString"; close MESSAGE; } sub wrapUp { close LOG if defined $useLog; }
Perl Script: batch
#! /usr/local/bin/perl # # Usage: # batch targetDatabase startAt [filesLaterThan] # # Description: # Retrieves file names, filter values and ert times from gllSsiEdr # for all files with a receivedAt time value greater than the value # of filesLaterThan. To retrieve the database information the # package dbqServer is used. For each row returned, the program testProc # is invoked with the row's parameters as testProc command line arguments. # Once processing is complete, batch sleeps untill startAt time arrives # the following day. Sleep is done in the package sleepTill. # # The format for the argument startAt is: # #: # # Where hours is for a 24 hour clock. For example: 2:00 is two o'clock in # the morining and 14:00 is two o'clock in the afternoon. # # The format for filesLaterThan is: # # mm/dd/yyyy [hh/mm/ss] # # for example: # # 6/12/1995 # 6/12/1995 12:00:30 # # # Written by: # John Rector # Jet Propulsion Laboratory # jar@next1.jpl.nasa.gov # # History: # June, 1995 1.0 - initial release # # Version: # 1.0 # Define the signals handled by this program. $SIG{'INT'} = 'sigHandler'; $SIG{'TERM'} = 'sigHandler'; # Add the name of the directory where Perl Packages (libraries) are located # at the beginning of the Perl standard array @INC. The require statment # allows us to access subroutines in the dbqServer and sleepTil packages. unshift (@INC, "/home/jar/Perl/Dbq"); require "dbqServer.pl" || die "Can't locate dbqServer.pl package\n"; require "sleepTill.pl" || die "Can't locate sleepTill.pl package\n"; require "mail.pl" || die "Can't locate mail.pl package\n"; # Check the number of parameters supplied on the command line. if ($#ARGV < 1) { print "\nToo few arguments supplied on command line.\n"; print "Usage: $0 targetDatabase startAt [filesLaterThan]\n\n"; exit 1; } # If the $filtesLaterThan values was supplied on the command line, use it. # Otherwise set the time to Jan 1, 1990, i.e., get all the files currently # defined for the file type. Notice that $filesLaterThan is used in # our query. Whenever we execute the statement, the current value for # $filesLaterThan will be used. if (defined $ARGV[2]) { $filesLaterThan = $ARGV[2]; } else { $filesLaterThan = "1/1/1900"; } $sql = "Select fileName, filter, ert, receivedAt from gllSsiEdr where receivedAt > \"$filesLaterThan\""; # Define the log file we'll be using. $log = "batch.log"; # Start a dbq process and have it connect to a database server. $ARGV[0] # is the name of the database to use. Note the package name "dbqServer" # in front of this subroutine name and those that follow. # If something went wrong, $dbqServer'dbqPid should not be defined, so # exit on that test. &dbqServer'connect ("MIPSDB1", $ARGV[0]); exit(1) unless (defined $dbqServer'dbqPid); # Loop until a SIGINT or SIGTERM signal is received. At that time, # $notDone is set to 0, or false, and the loop will exit. $notDone = 1; while ($notDone) { # sleep until the time supplied in $ARGV[1]. Then do some work. &sleepTill'tomorrow ($ARGV[1]); undef $cmd; while (1) { print "CMD> "; $input = ; last if $input =~ /^go/; last if $input =~ /^exit/; $cmd .= $input; } last if $input =~ /^exit/; # Execute the query. If @dbqServer'rows is defined, get the values # for each row returned and process it. If an error occured. write # it to the log file. # Note: when a row is returned, a new value is assigned to # $filesLaterThan which is defined in our query command ($sql). # The next time the query is run, the last value returned will # be used, so only files later than that value are returned. &dbqServer'cmd ($cmd); if (defined @dbqServer'rows) { foreach $row (@dbqServer'rows) { ($fileName, $filter, $ert, $filesLaterThan) = split ('\t', $row); $message = "batch.p: Processing file: $fileName\n"; &mail'message ($message); system ("testProc", "$fileName", "$filter", "$ert"); if ($? >> 8) { $message = "testProc failed with status: " . ($? >> 8); &mail'message ($message); } } } elsif (defined @dbqServer'error) { print LOG @dbqServer'error; } } $dbqServer'disconnect; exit 0; ####################### # subroutine sigHandler ####################### # Captures SIGINT and SIGTERM. Sets the main loop variable, so the program # exits on the next pass through the loop. sub sigHandler { $notDone = 0; }
How To Create A Dbq
Source: https://www-mipl.jpl.nasa.gov/mdms/Dbms/dbq.html
Posted by: paigewilier88.blogspot.com
0 Response to "How To Create A Dbq"
Post a Comment